Transformer网络-Self-attention is all your need
一、Transformer
Transformer最开始用于机器翻译任务,其架构是seq2seq的编码器解码器架构。其核心是自注意力机制: 每个输入都可以看到全局信息,从而缓解RNN的长期依赖问题。
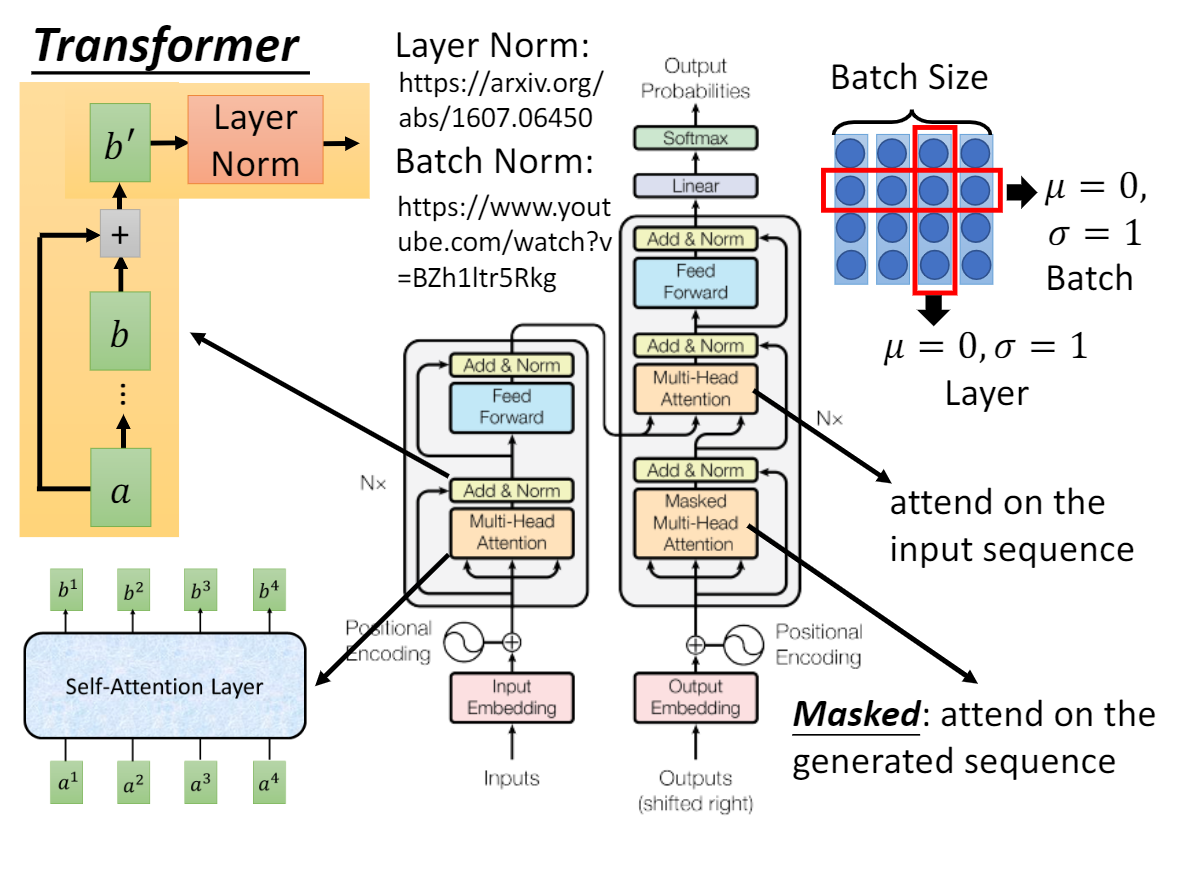
输入: (待学习的)输入词嵌入 + 位置编码(相对位置)
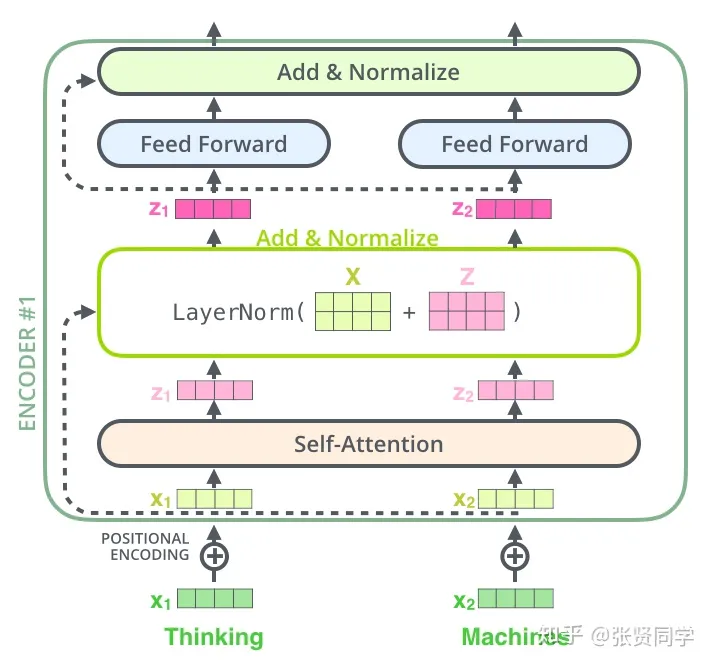
编码器结构: 6层编码器: 一层编码器 = 多头注意力+残差(LN) + FFN+残差(LN)
输出:每一个位置上输出预测概率分布(K类类别分布)
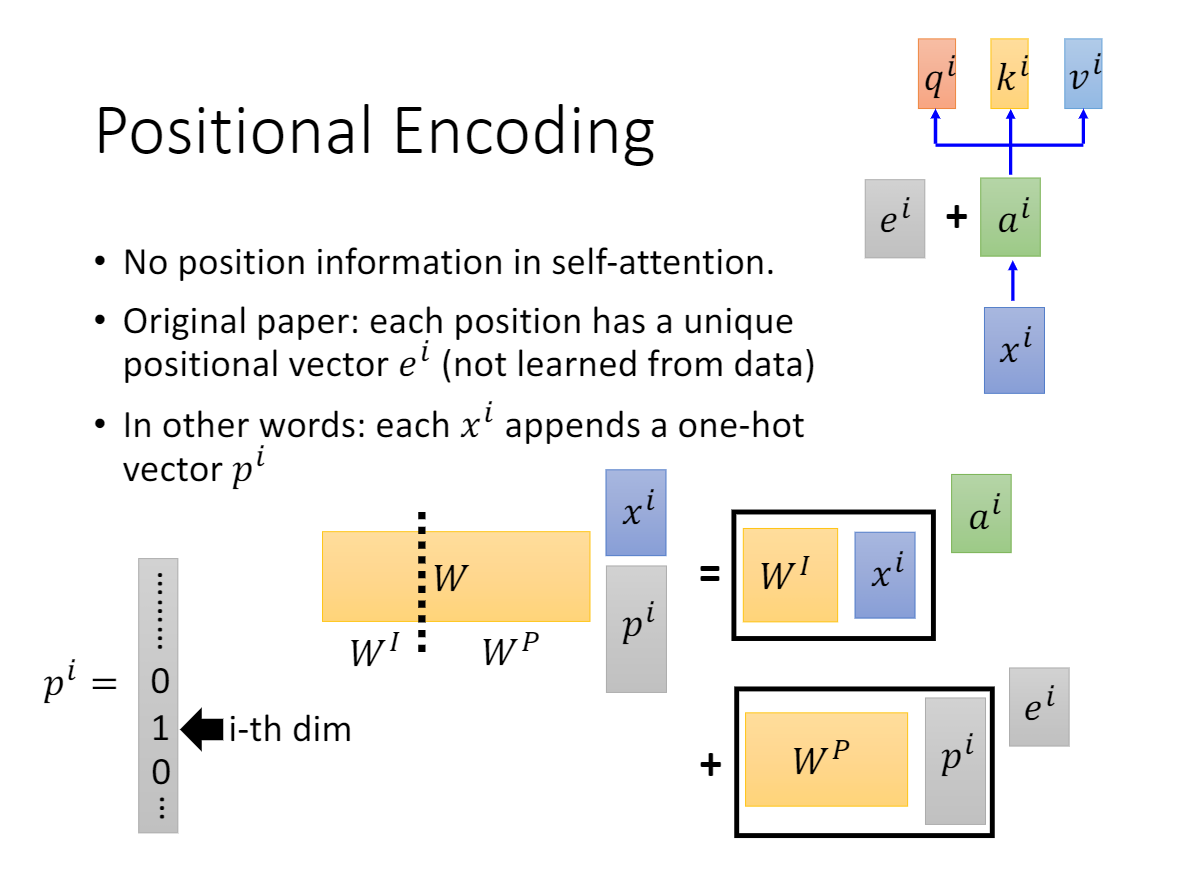
1.1 自注意力
分解式
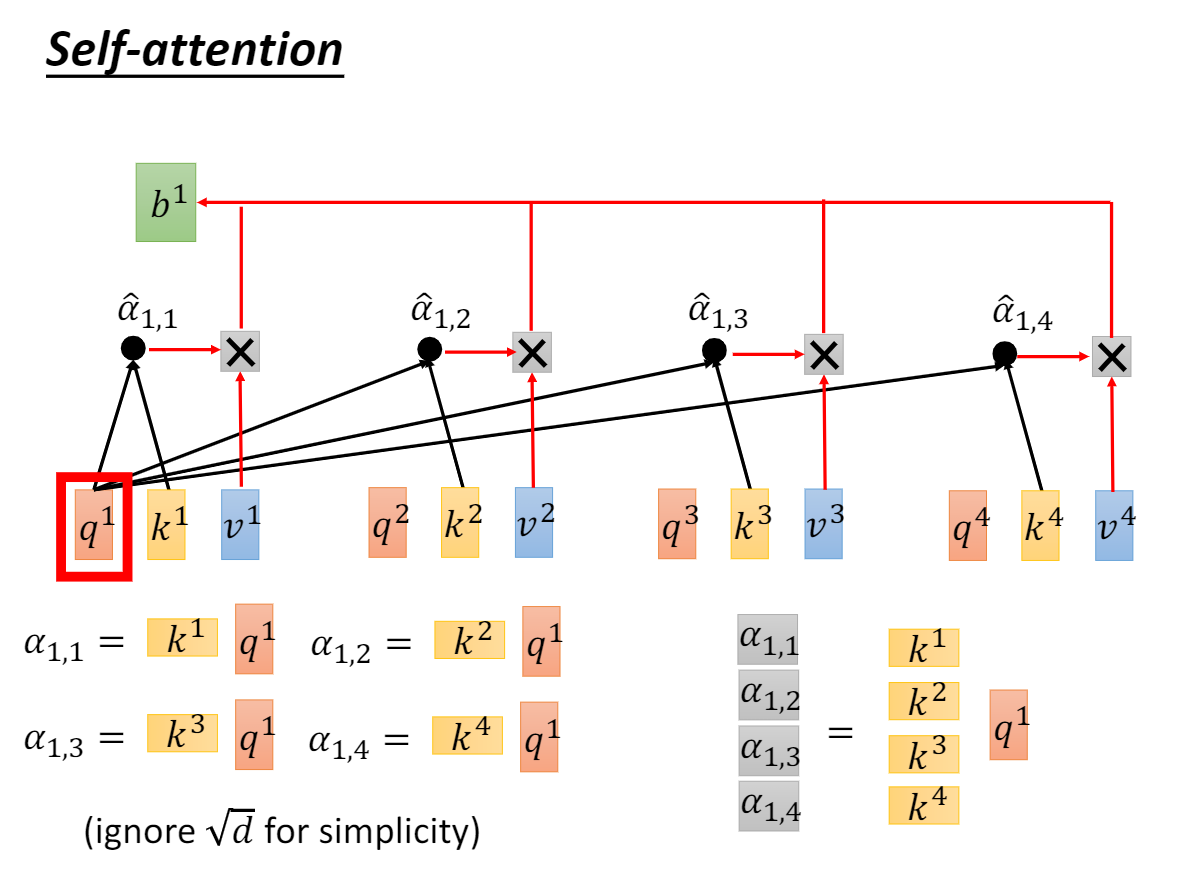
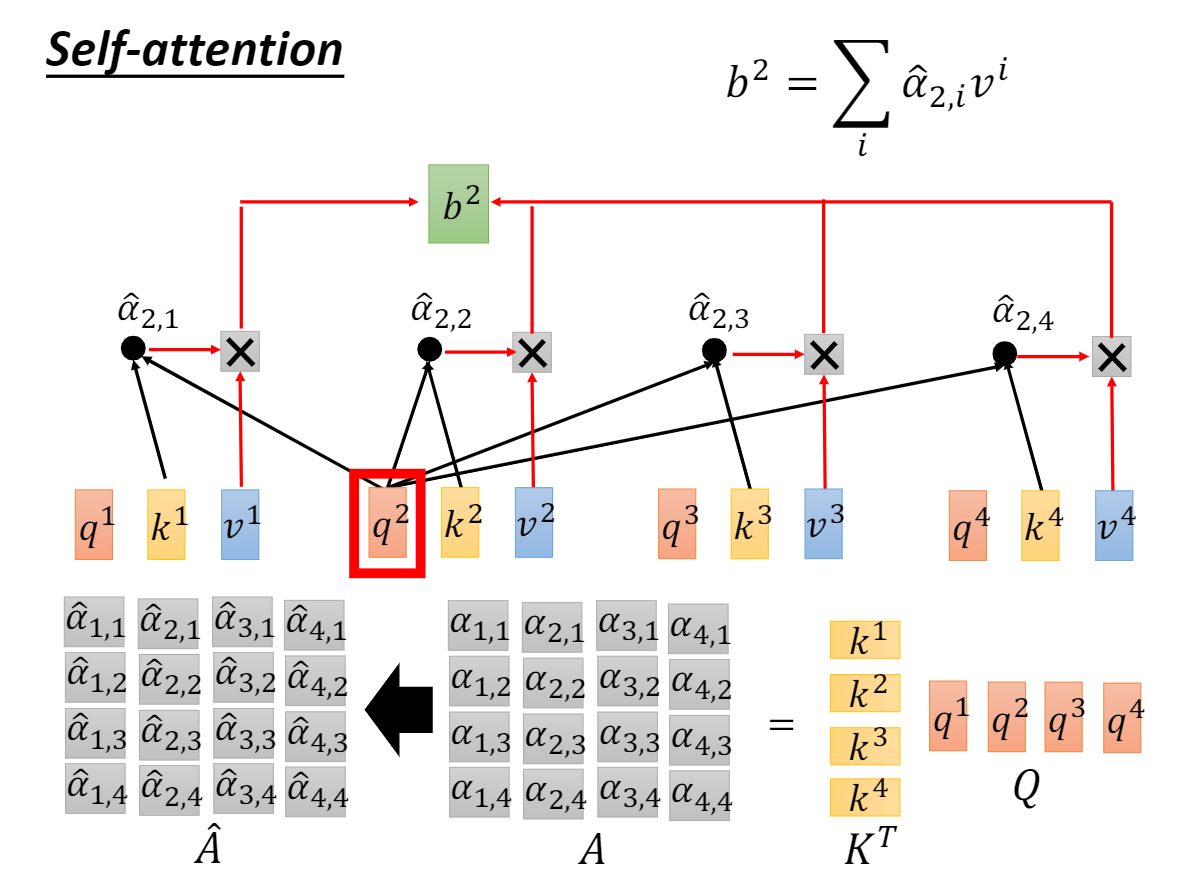
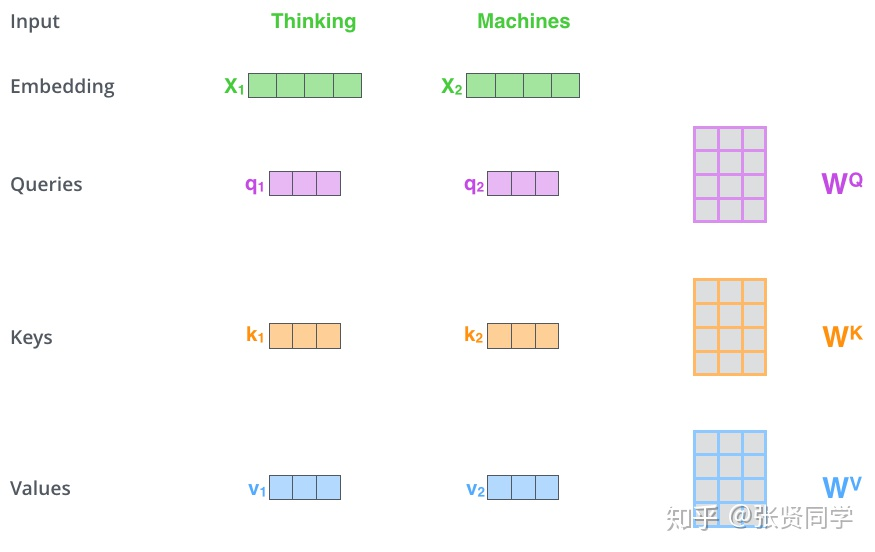
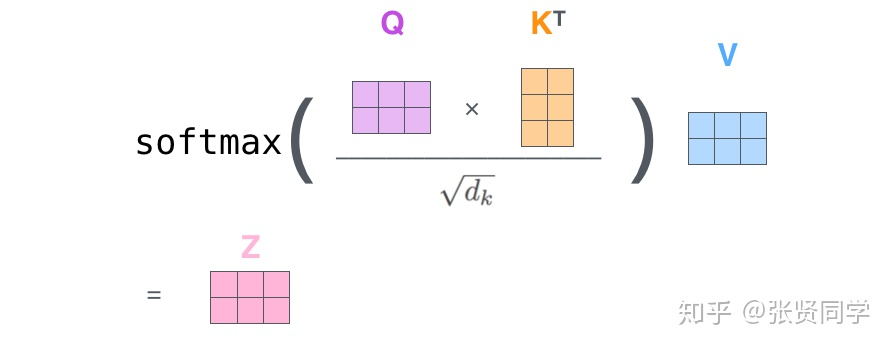
缩放内积注意力
1. 自注意力的优势
a. 计算开销,计算可并行 (嵌入维度d,序列长度n,计算复杂度O(n^2d))
b. 建模长期依赖 (稳定训练过程)
2. 自注意力缩放(内积过大,softmax饱和)
We suspect that for large values d_k, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.To counteract this effect, we scale the dot products by sqrt(d_k)
如上为原文。作者怀疑,如果Q和K的维度特别大,会使得内积后的值也大。从而使softmax进入梯度极小的区域(类似于sigmoid的饱和区域)。 这样容易导致梯度消失。
所以,他们将内积值除以sqrt(d_k),进行一个缩放,而又不破坏相对比例。
多头注意力机制(multi-head attention)
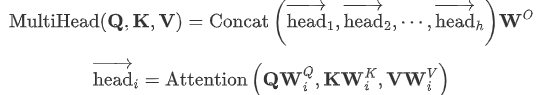
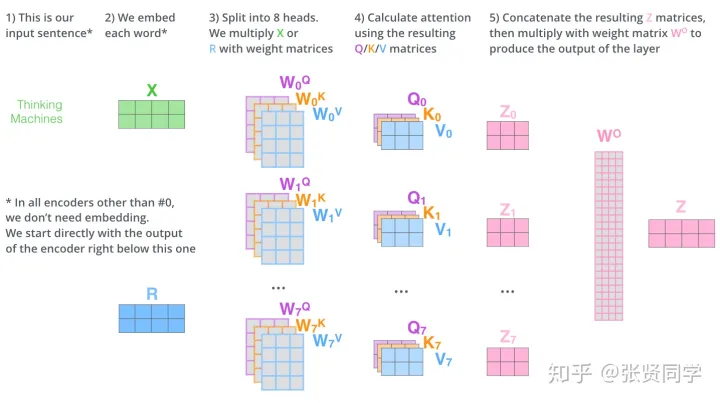
Transformer 提出多头注意力机制(不同头结果拼起来,再做线性变换),增强了 attention 层的能力(参数量不变)。解释:
- 它扩展了模型关注不同位置的能力。不同注意力头,关注不同的位置。长距离依赖
- 多头注意力机制赋予 attention 层多个“子表示空间(训练之后,每组注意力可以看作是把输入的向量映射到一个”子表示空间“)
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
参数说明如下:
- embed_dim:最终输出的 K、Q、V 矩阵的维度,这个维度需要和词向量的维度一样
- num_heads:设置多头注意力的数量。如果设置为 1,那么只使用一组注意力。如果设置为其他数值,那么 num_heads 的值需要能够被 embed_dim 整除
- dropout:这个 dropout 加在 attention score 后面
定义 MultiheadAttention 的对象后,调用时传入的参数如下。
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
- query:对应于 Query 矩阵,形状是 (L,N,E) 。其中 L 是输出序列长度,N 是 batch size,E 是词向量的维度
- key:对应于 Key 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- value:对应于 Value 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- key_padding_mask:如果提供了这个参数,那么计算 attention score 时,忽略 Key 矩阵中某些 padding 元素,不参与计算 attention(序列长度不同)。形状是 (N,S)。其中 N 是 batch size,S 是输入序列长度。
- 如果 key_padding_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 key_padding_mask 是 BoolTensor,那么 True 对应的位置会被忽略
- attn_mask:计算输出时,忽略某些位置。形状可以是 2D (L,S),或者 3D (N∗numheads,L,S)。其中 L 是输出序列长度,S 是输入序列长度,N 是 batch size。
- 如果 attn_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 attn_mask 是 BoolTensor,那么 True 对应的位置会被忽略
在实际中,K、V 矩阵的长度一样,而 Q 矩阵的序列长度可不一样。这种情况发生在:在解码器部分的encoder-decoder attention层中,Q 矩阵是来自解码器下层,而 K、V 矩阵则是来自编码器的输出。
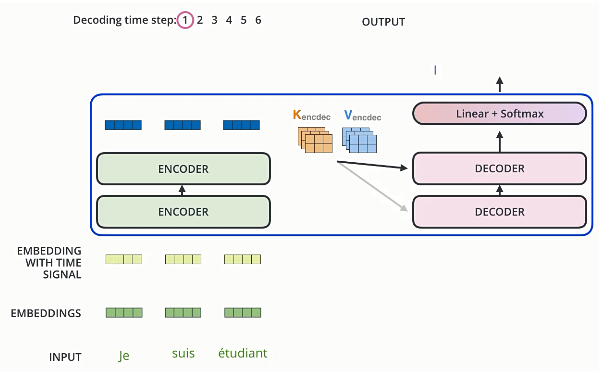
2. Encoder 和 Decoder
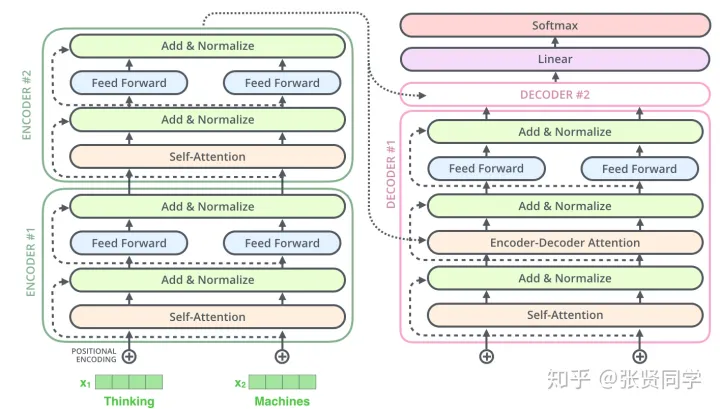
编码器就是编码器层(多头注意力+(残差+LN),FFN+(残差+LN))的堆叠。
解码器
Self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.We need to prevent leftward information flow in the decoder to preserve the auto-regressive property.We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
为了保持自回归的性质,要保持从左往右的顺序 (这种情况下,不能利用要预测的未来来推断过去)。 这里将当前token以后的进行mask (即将注意力得分加上-inf,将其变成无穷小,使其注意力系数极小接近于无) [exp(-inf) = 0]
GAT也是这样做的,只不过mask的是非邻居结点 (避免信息泄露,从而让模型学不好)。
# 把 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10(系数无穷小)
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale if mask is not None: attention = attention.masked_fill(mask == 0, -1e10) attention = self.do(torch.softmax(attention, dim=-1)) x = torch.matmul(attention, V)
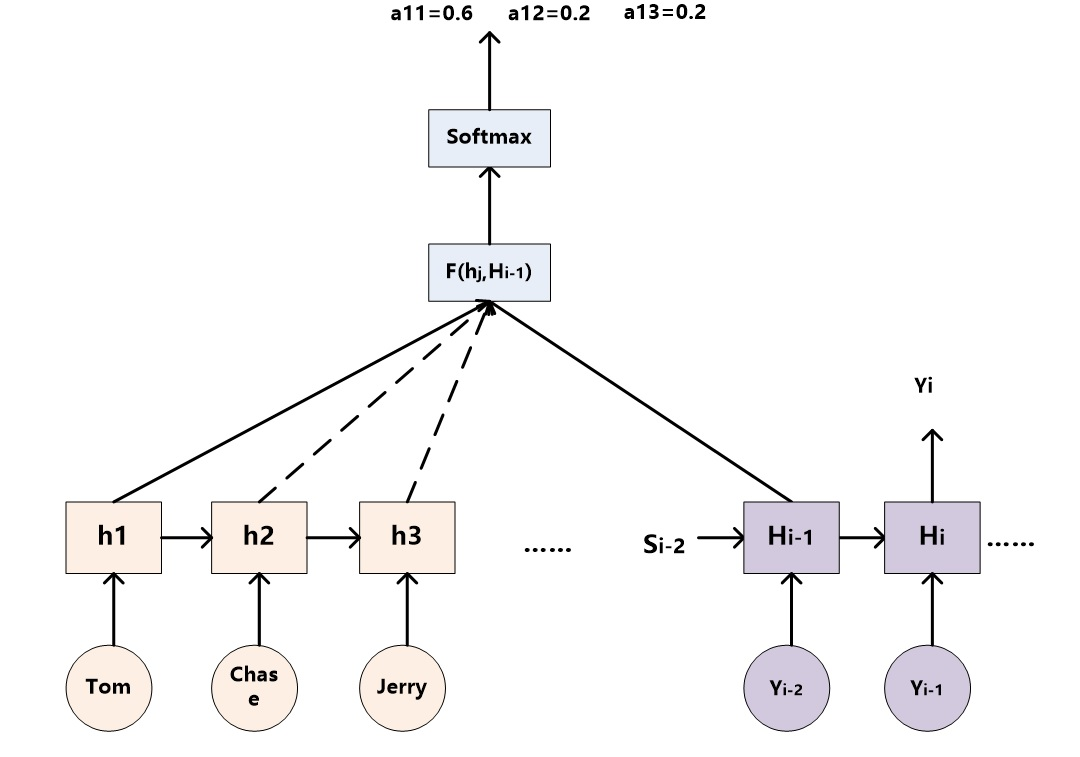
交叉注意力层(Decoder-Encoder Attention, Decoder到Encoder输出的潜表示)
使用前一层的输出来构造 Query 矩阵,而 Key 矩阵和 Value 矩阵来自于编码器最终的输出(seq2seq都是这样的,预测当前输出时,不仅看之前的输出,同时也对输入隐状态进行关注)
预测
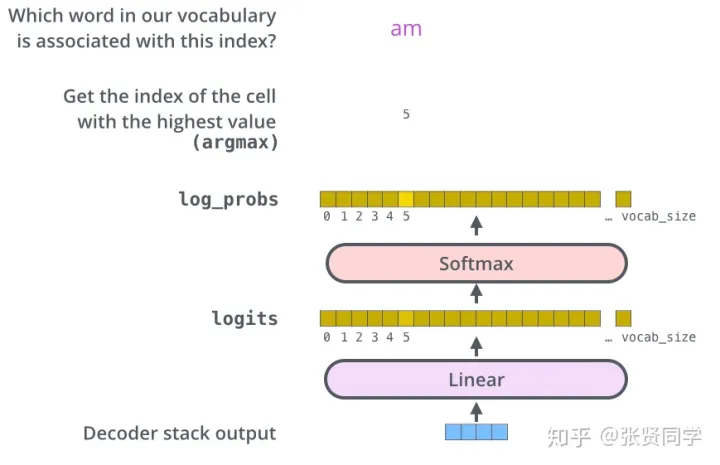
每一个位置有一个分类损失;总的损失就是每个位置损失之和。
训练

让我们假设输出词汇表只包含 6 个单词(“a”, “am”, “i”, “thanks”, “student”, and “”(“”表示句子末尾))。
这种架构本就可以用来做语言模型,只不过这里做了seq2seq的翻译。
如果训练数据中本身就有很多句子对,就可以直接通过语言模型实现翻译,例如GPT架构。
学习笔记,配图参考知乎-张贤同学、李宏毅机器学习。
热门相关:无量真仙 天启预报 天启预报 豪门闪婚:帝少的神秘冷妻 霸皇纪